前言
本篇內容來自李宏毅老師於Youtube的上傳的ML相關課程。(Link1) (Link2)
Example Application
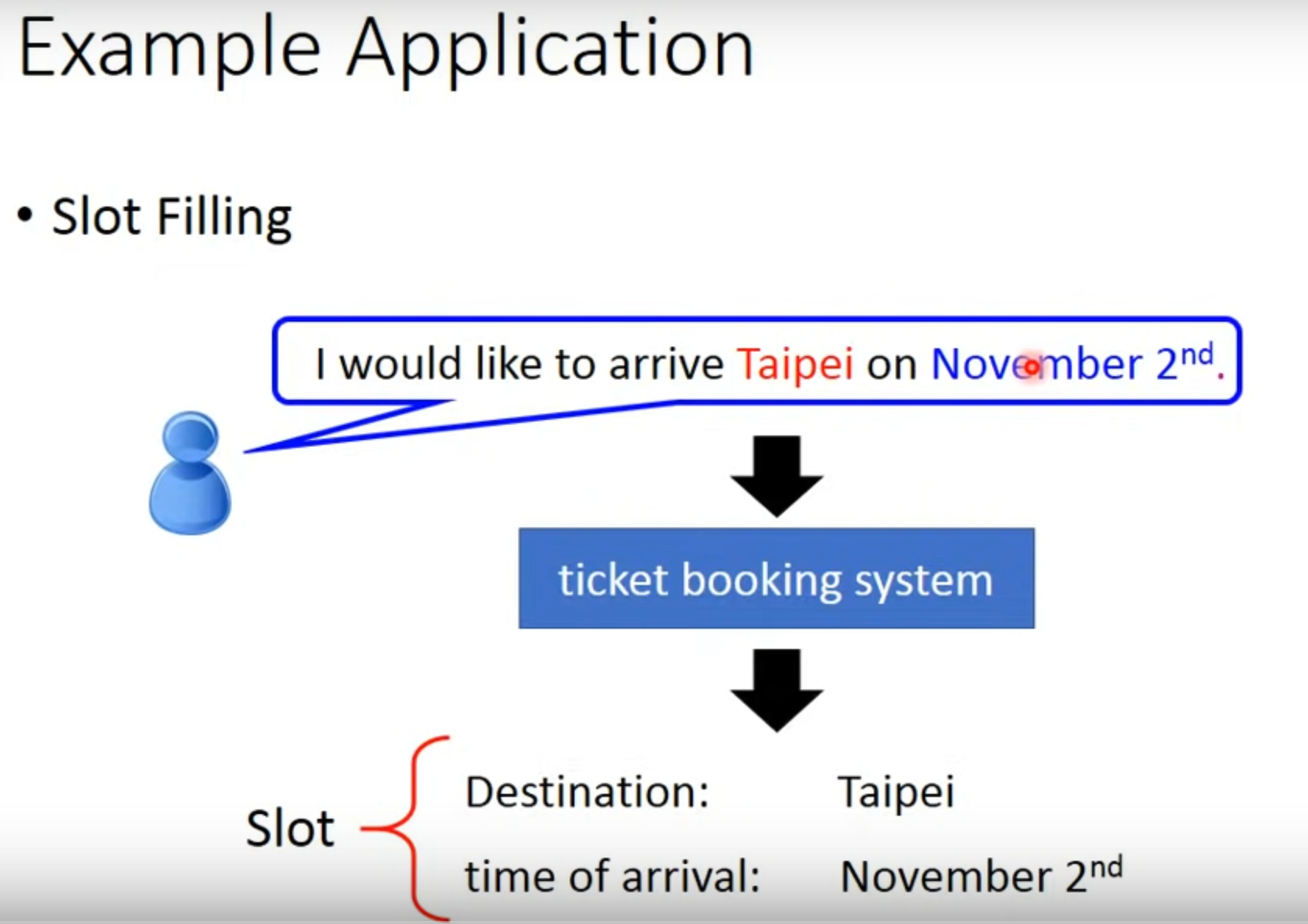
課程說明時,使用一個Slot Filling的例子。比如上圖中system中有兩個slot: Destination & time of arrival,system需要能將用戶的語句中相應的部分填入Slot中。
解法
Naive: Feedforward network
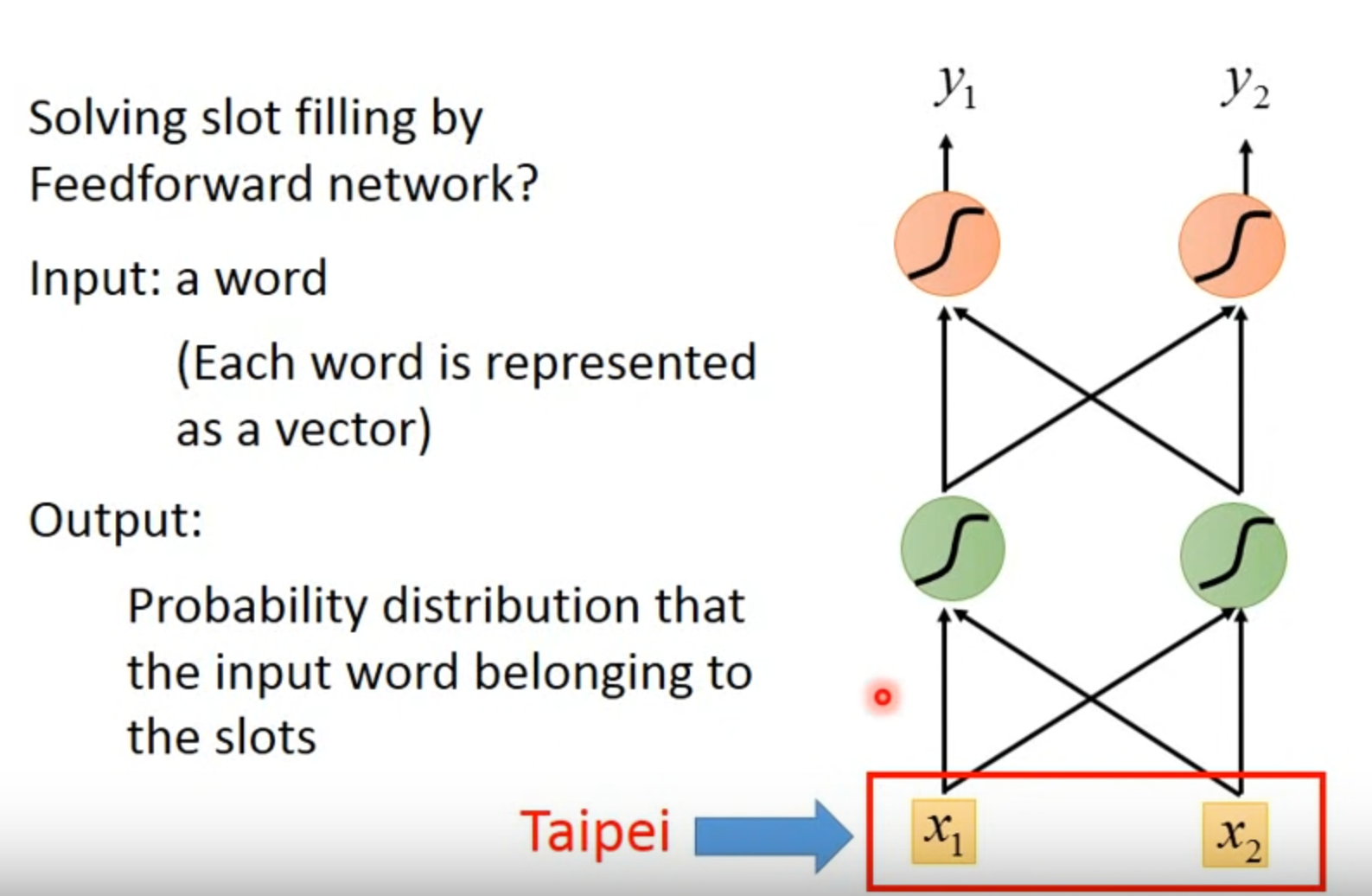
直接將word轉為vector後丟到簡單的神經網路內,轉換的方法比如可以簡單的用 1-of-N encoding。
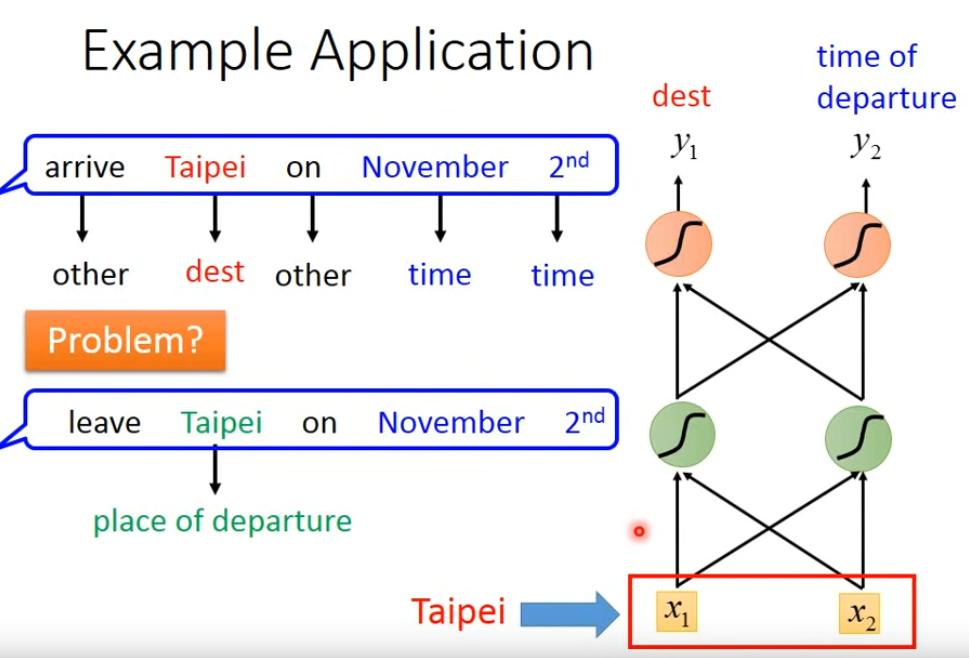
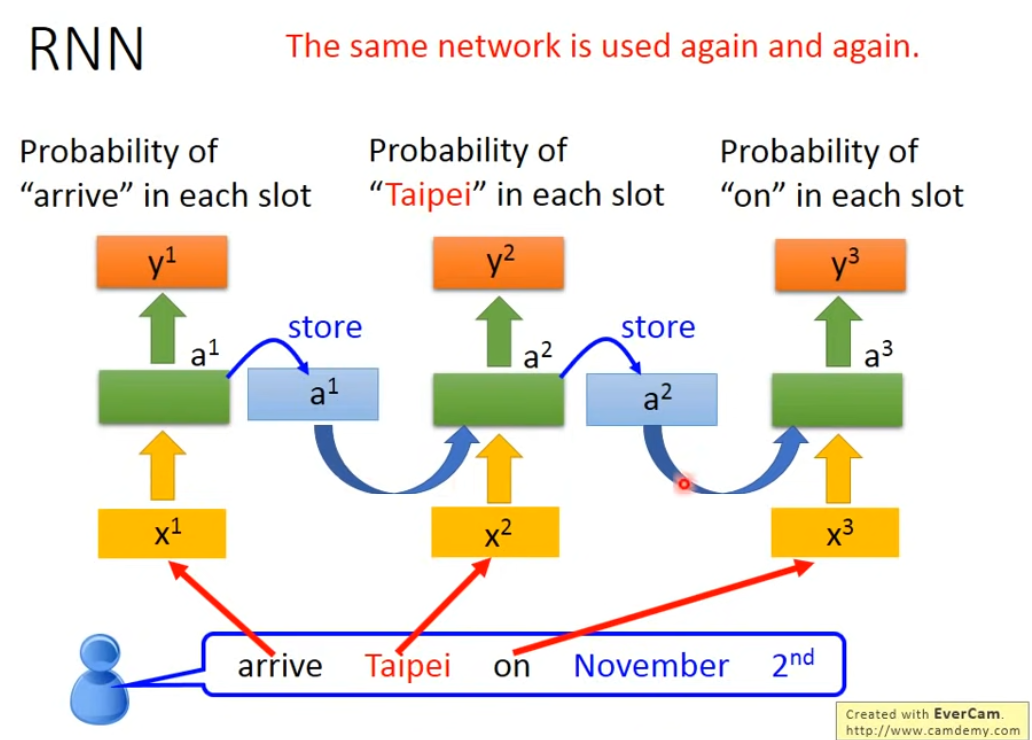
但簡單的Feedforward network無法區分上邊“Taipei”一次是出發地還是目的地的含義,這個時候希望神經網路可以參考到“Taipei”前面的詞彙,如這邊的“arrive”&“leave”,即希望有記憶。這種有記憶的神經網路稱為 Recurrent Neural Network(RNN)
LSTM(Long Short-term Memory)
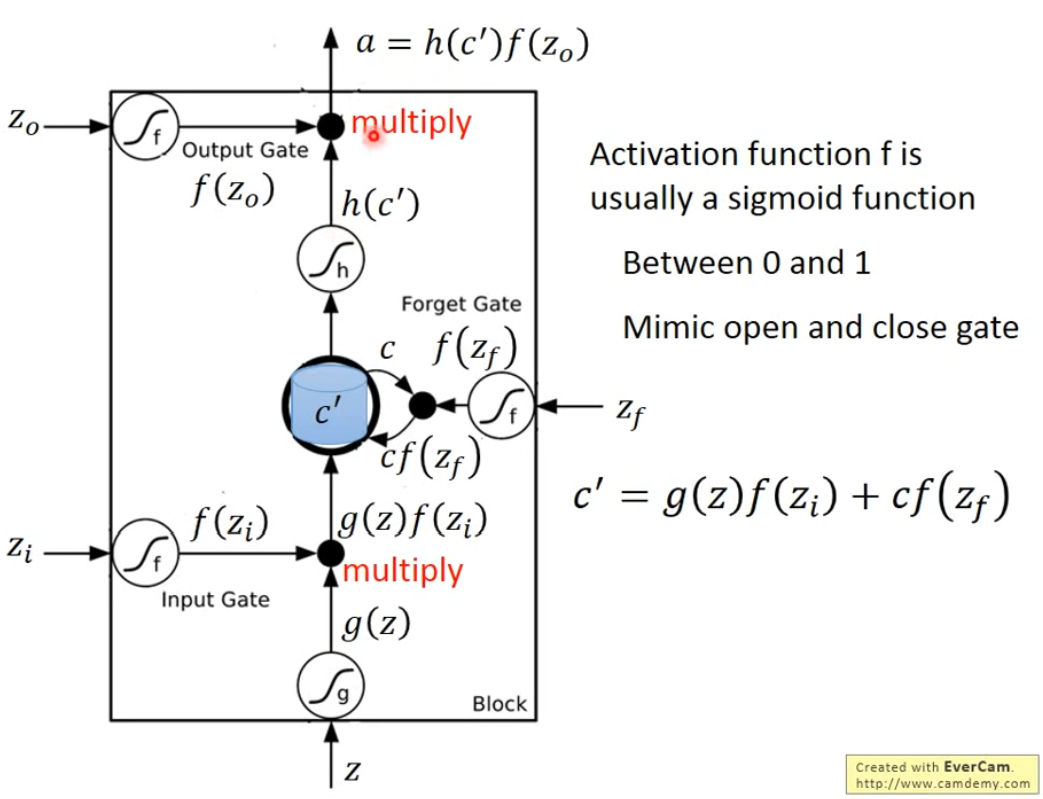
如上用三個Gate(input/forget/output)來控制memory cell。例子見視頻。
LSTM的一個Memory Cell即對應普通Network中的一個神經元。
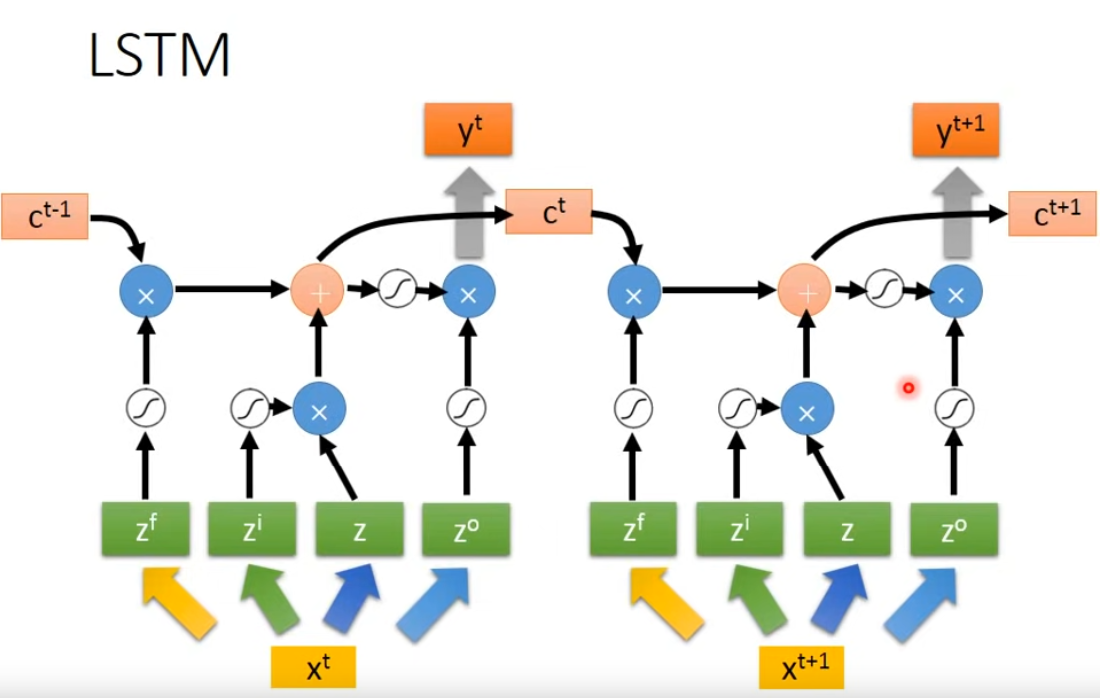
LSTM的簡單形態如上,對於輸入
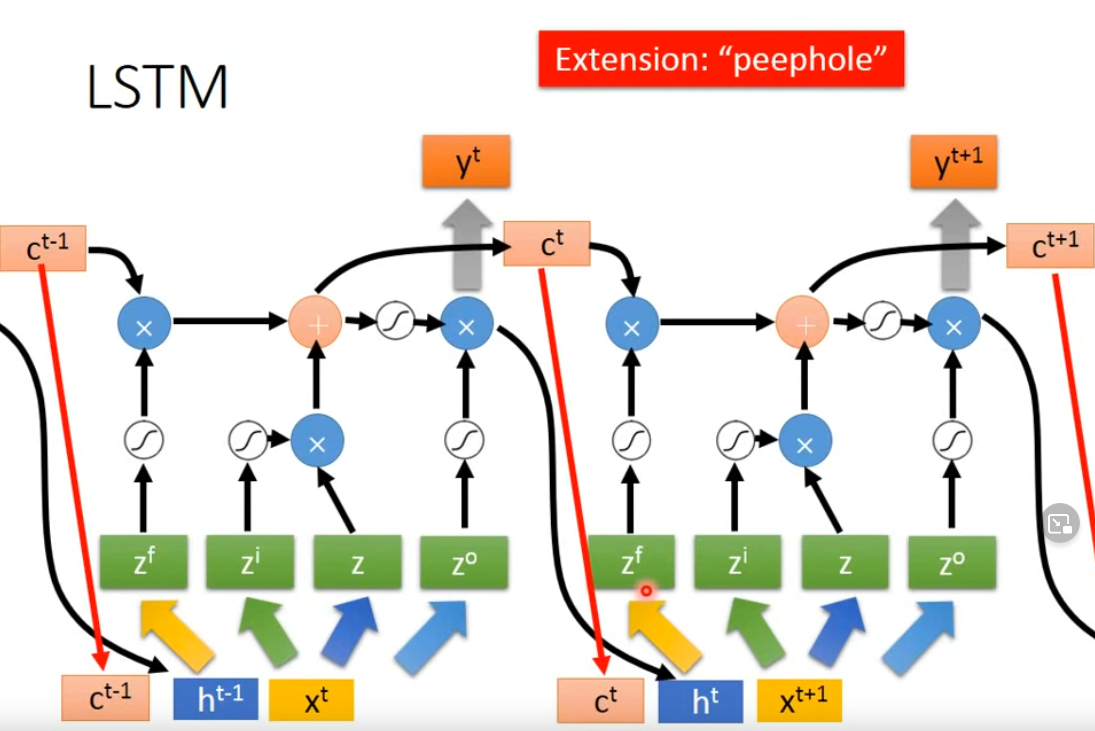
其實完整的LSTM形態中,在輸入端還會參考上一次Memory cell的輸出
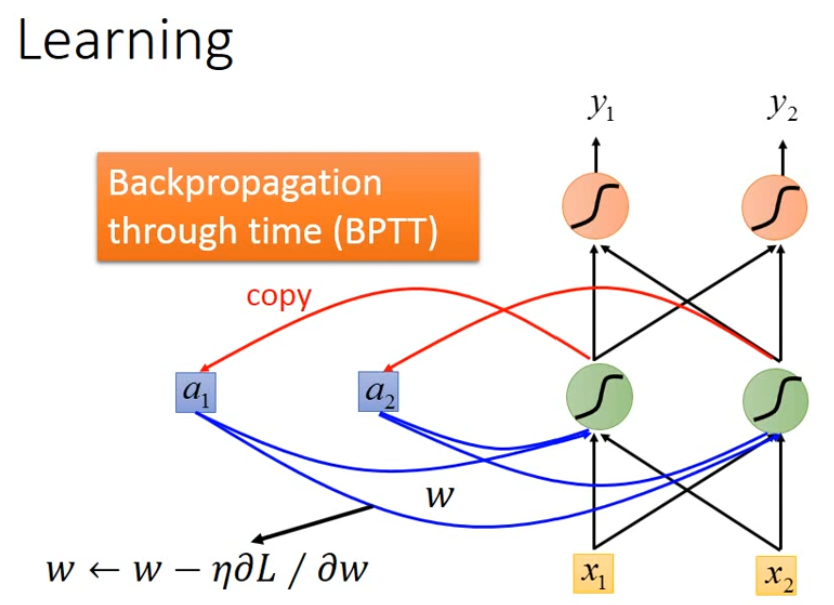
RNN如何進行Learning
同樣是定義loss function,將其最小化。這邊我們將輸入
同樣使用gradient descent進行訓練,即用Backpropagation,在RNN中用Backpropagation through time(BPTT)。
但其實RNN的training是比較困難的,其Learning Curve常會發生波動。
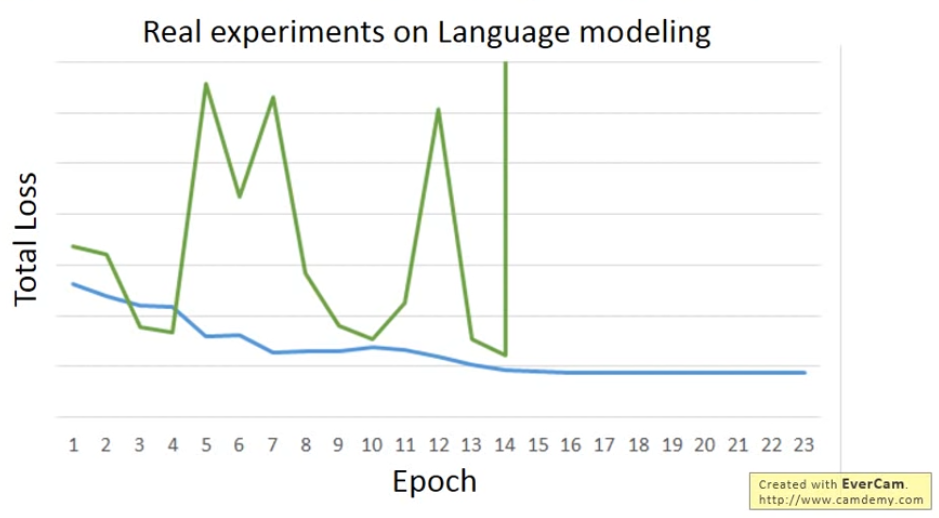
這其實是因為RNN的error surface會非常平坦或非常陡峭,可以使用Clipping來解決,即把Gradient限制在某個threshold之下。其實用LSTM可以解決gradient vanishing的問題(即error surface上過於平坦的部分),但不能處理gradient explode(即太崎嶇的部分)。