作者與來源
Defferrard, Michaël, Xavier Bresson, and Pierre Vandergheynst. "Convolutional neural networks on graphs with fast localized spectral filtering." Advances in neural information processing systems 29 (2016).
背景與貢獻
CNN offer an efficient architecture to extract highly meaningful statistical patterns in large-scale and high-dimensional datasets.User data on social networks, gene data on biological regulatory networks, log data on telecommunication networks, or text documents on word embeddings are important examples of data lying on irregular or non-Euclidean domains that can be structured with graphs, which are universal representations of heterogeneous pairwise relationships.A generalization of CNNs to graphs is not straightforward as the convolution and pooling operators are only defined for regular grids. This makes this extension challenging, both theoretically and implementation-wise.
因此引出本paper的五點貢獻: * Spectral formulation. A spectral graph theoretical formulation of CNNs on graphs built on established tools in graph signal processing (GSP). 使用GSP工具產生作用於graph CNN的譜圖理論公式。 * Strictly localized filters. Enhancing , the proposed spectral filters are provable to be strictly localized in a ball of radius K, i.e. K hops from the central vertex. * Low computational complexity. The evaluation complexity of our filters is linear w.r.t. the filters support’s size
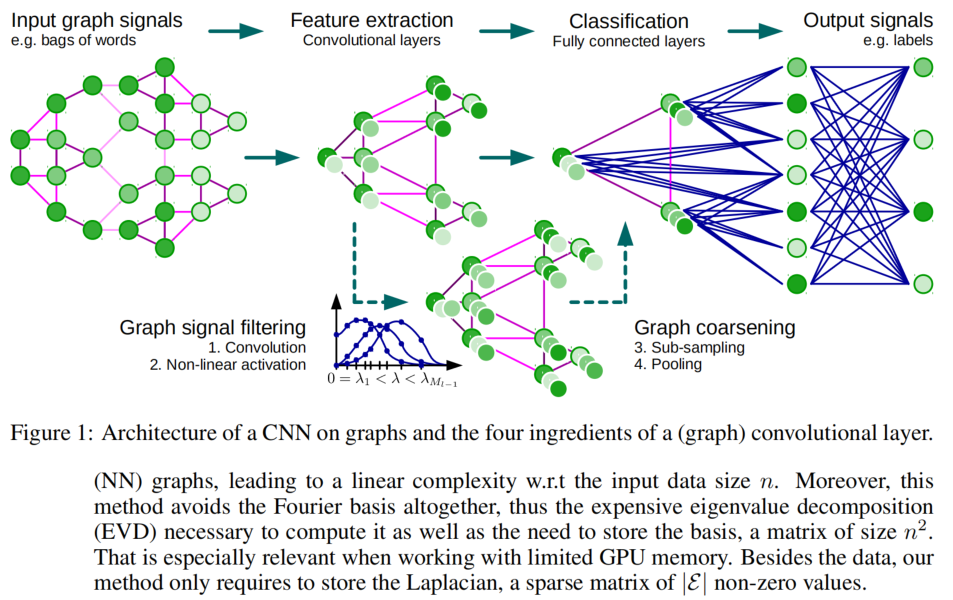
提出的方法
將CNN推廣到graph需要經過三個步驟: 1. the design of localized convolutional filters on graphs 2. a graph coarsening procedure that groups together similar vertices 3. a graph pooling operation that trades spatial resolution for higher filter resolution.
Learning Fast Localized Spectral Filters
In other post.
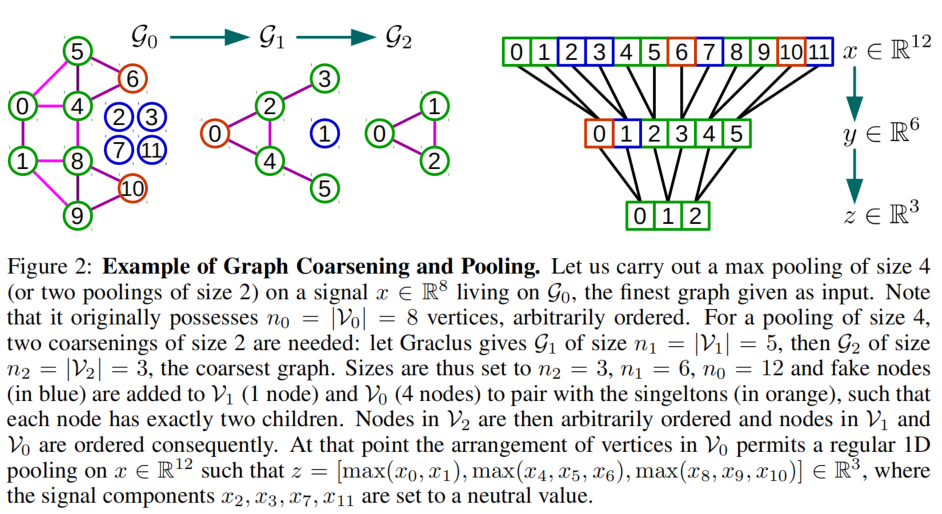
Graph Coarsening
The pooling operation requires meaningful neighborhoods on graphs, where similar vertices are clustered together. Doing this for multiple layers is equivalent to a multi-scale clustering of the graph that preserves local geometric structures. While there exist many clustering techniques, e.g. the popular spectral clustering, we are most interested in multilevel clustering algorithms where each level produces a coarser graph which corresponds to the data domain seen at a different resolution. In this work, we make use of the coarsening phase of the Graclus multilevel clustering algorithm , which has been shown to be extremely efficient at clustering a large variety of graphs.
Fast Pooling of Graph Signals
Pooling operations are carried out many times and must be efficient. Hence, a direct application of the pooling operation would need a table to store all matched vertices. That would result in a memory inefficient, slow, and hardly parallelizable implementation. It is however possible to arrange the vertices such that a graph pooling operation becomes as efficient as a 1D pooling. We proceed in two steps: (i) create a balanced binary tree and (ii) rearrange the vertices.
實驗
Notation:
We use the following notation when describing network architectures: FC
Revisiting Classical CNNs on MNIST
To validate our model, we applied it to the Euclidean case on the benchmark MNIST classification problem, a dataset of 70,000 digits represented on a 2D grid of size 28 × 28. 將本文提出的model應用於傳統的CNN任務,比較本模型與傳統模型的效果。因為本文提出的model是針對graph,而MNIST的手寫圖像辨識圖片2D grid也可以看做是一種graph,理應有不錯表現。

由Table1可見實驗結果是兩者的辨識準確度都差不多,極高。
Text Categorization on 20NEWS
To demonstrate the versatility of our model to work with graphs generated from unstructured data, we applied our technique to the text categorization problem on the 20NEWS dataset which consists of 18,846 (11,314 for training and 7,532 for testing) text documents associated with 20 classes.
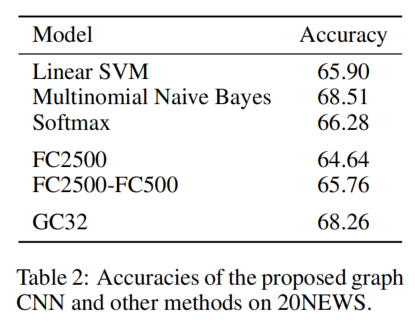
由上Table2結果可見,除了與Multinomial Naive Bayes Classifier有微小差距,本文提出的模型擊敗了其他所有模型,包括需要更多參數的FC(Full Connected) Network。
Comparison between Spectral Filters and Computational Efficiency
本文提出的model預期將由更優的計算複雜度。
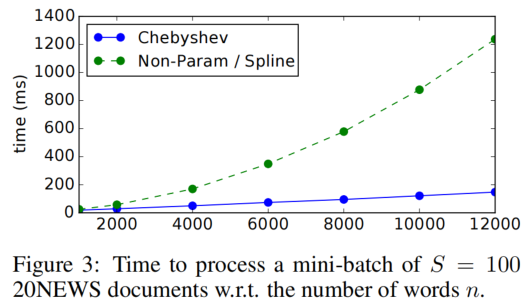
由上Figure3可見,相較於前人提出的Spline,本文提出的(Chebyshev/ChebyNet)在 20NEWS mini-batch任務上所花的時間更少,且大致隨問題規模呈現線性增長。
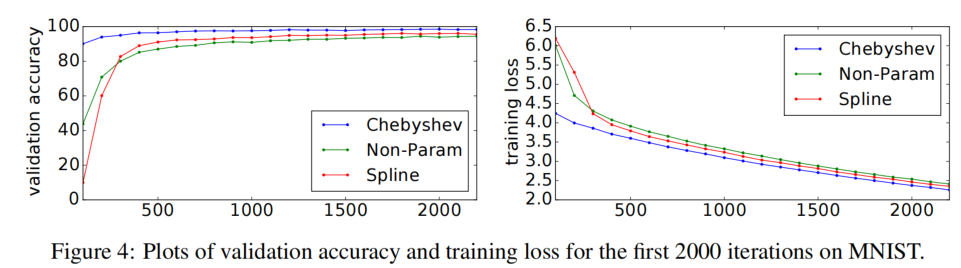
由上Figure4可見,相較於前人模型,ChebyNet提供了更高的Validation Accuracy和更低的Training Loss。
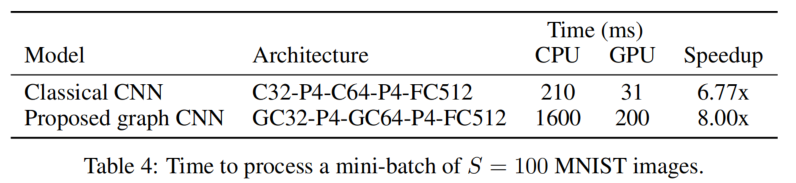
上Table4顯示出當本模型的計算平台從CPU遷移至GPU時,獲得的計算加速倍率高於傳統CNN的遷移,體現出與GPU平台的高適配性。
Influence of Graph Quality
The learned filters’ quality and the classification performance critically depends on the quality of graph.
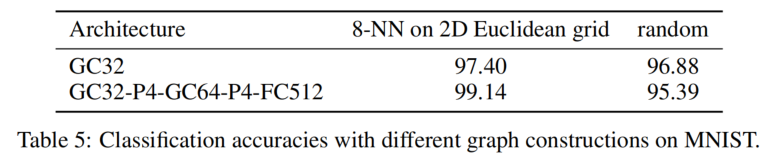
如上Table5,但我們不用K-NN的方式建構圖,而完全使用random方式建構時,本文model的精確度將會有一個較大的下滑,這是因為graph structure的缺失導致filter無法有效的提取出有意義的feature。

如上Table6,當使用不同方法建構graph(包括bag-of-words,word2vec,LSHForest)時得到的分類精確度有較大差距,也體現出建構graph階段的重要性,一個高質量graph對訓練結果的重要性。
總結與未來方向
In this paper, we have introduced the mathematical and computational foundations of an efficient generalization of CNNs to graphs using tools from GSP.Besides, we addressed the three concerns raised: * we introduced a model whose computational complexity is linear with the dimensionality of the data * we confirmed that the quality of the input graph is of paramount importance * we showed that the statistical assumptions of local stationarity and compositionality made by the model are verified for text documents as long as the graph is well constructed
Future Works: * enhance the proposed framework with newly developed tools in GSP * explore applications of this generic model to important fields where the data naturally lies on graphs, which may then incorporate external information about the structure of the data rather than artificially created graphs which quality may vary as seen in the experiments