前言
因為做林軒田老師作業的原因接觸到了由同系Machine Learning Group團隊開發的LIBLINEAR套件。該套件提供了對超大數據量下之各種線性分類器的支持,包括:
- L2-regularized classifiers
- L2-loss linear SVM, L1-loss linear SVM, and logistic regression (LR)
- L1-regularized classifiers (after version 1.4)
- L2-loss linear SVM and logistic regression (LR)
- L2-regularized support vector regression (after version 1.9)
- L2-loss linear SVR and L1-loss linear SVR.
- L2-regularized one-class support vector machines (after version 2.40)
作者環境
1
2
3
LIBLINEAR Version: 2.43
Python Version: Anaconda with pyhton 3.8
IDE: Pycharm
1 | LIBLINEAR Version: 2.43 |
python下套件安裝
在V2.43後安裝已經非常方便,直接使用pip安裝即可。
1 | pip install -U liblinear-official |
當然,LIBLINEAR也支持不同的平台和語言,更多的安裝方式可以在上邊的MORE INFO中找到。 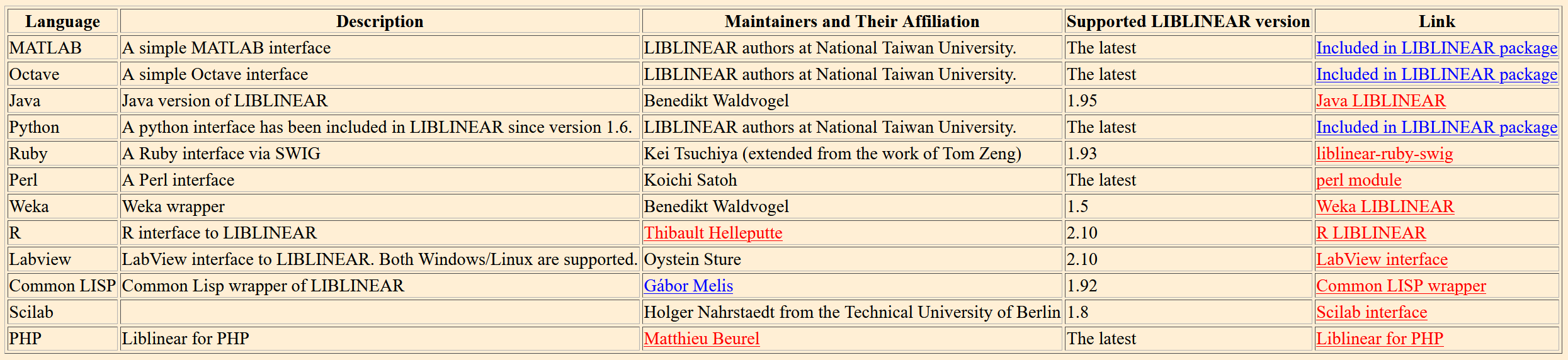
Data格式
LIBLINEAR對資料格式有特別的要求,在應用套件之前應該先將原本的data set處理為目標格式。其格式形式為:Label feature_index_1:feature_value_1 feature_index_2:feature_value_2 ... feature_index_N:feature_value_N 例如(套件自帶範例heart_scale): 1
2
3
4
5
6
7
8
9
10+1 1:0.708333 2:1 3:1 4:-0.320755 5:-0.105023 6:-1 7:1 8:-0.419847 9:-1 10:-0.225806 12:1 13:-1
-1 1:0.583333 2:-1 3:0.333333 4:-0.603774 5:1 6:-1 7:1 8:0.358779 9:-1 10:-0.483871 12:-1 13:1
+1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1 8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
-1 1:0.458333 2:1 3:1 4:-0.358491 5:-0.374429 6:-1 7:-1 8:-0.480916 9:1 10:-0.935484 12:-0.333333 13:1
-1 1:0.875 2:-1 3:-0.333333 4:-0.509434 5:-0.347032 6:-1 7:1 8:-0.236641 9:1 10:-0.935484 11:-1 12:-0.333333 13:-1
-1 1:0.5 2:1 3:1 4:-0.509434 5:-0.767123 6:-1 7:-1 8:0.0534351 9:-1 10:-0.870968 11:-1 12:-1 13:1
+1 1:0.125 2:1 3:0.333333 4:-0.320755 5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.5
+1 1:0.25 2:1 3:1 4:-0.698113 5:-0.484018 6:-1 7:1 8:0.0839695 9:1 10:-0.612903 12:-0.333333 13:1
+1 1:0.291667 2:1 3:1 4:-0.132075 5:-0.237443 6:-1 7:1 8:0.51145 9:-1 10:-0.612903 12:0.333333 13:1
+1 1:0.416667 2:-1 3:1 4:0.0566038 5:0.283105 6:-1 7:1 8:0.267176 9:-1 10:0.290323 12:1 13:1
Python中使用
常用函數:
svm_read_problem

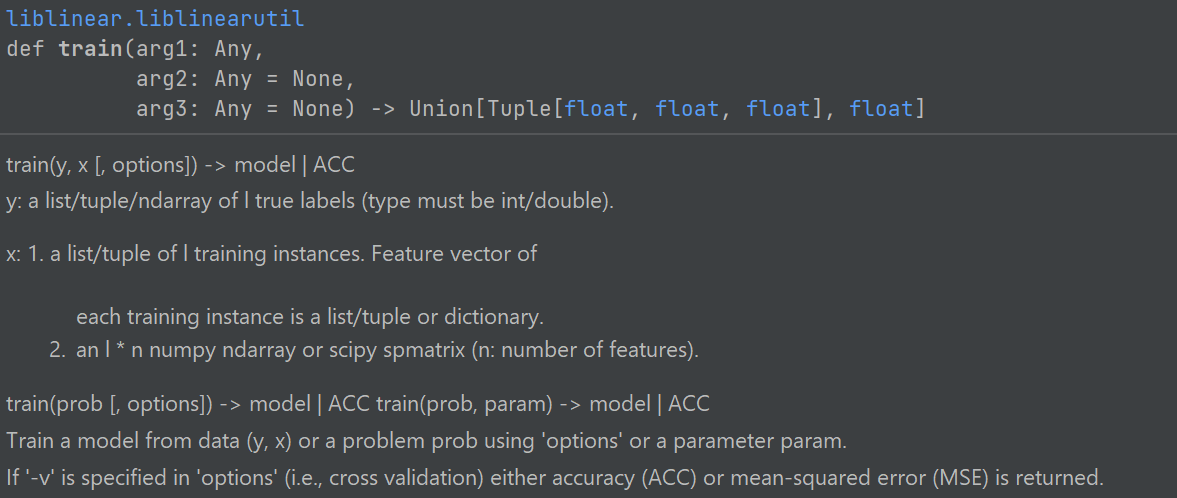
train
predict
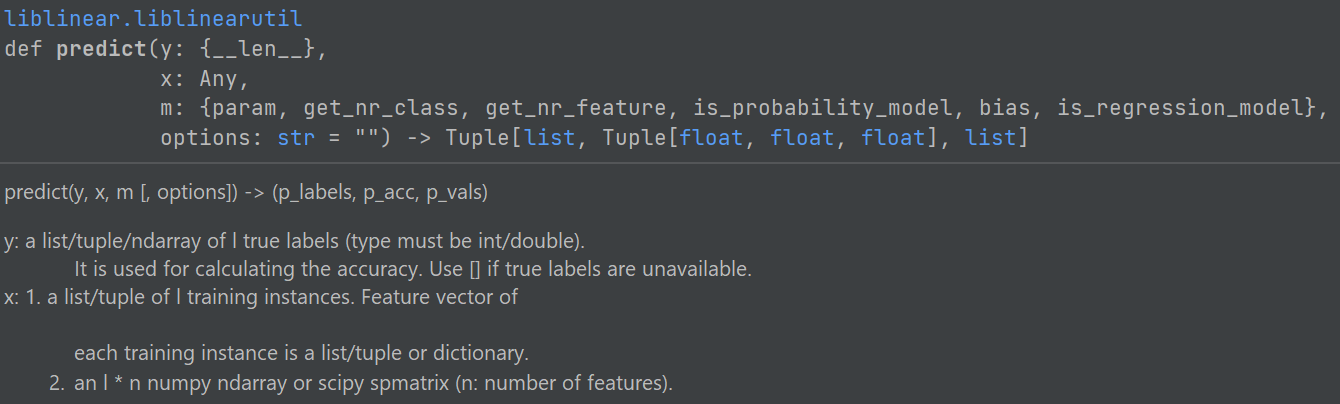
函數參數詳情:見
例子:
1 | from liblinear.liblinearutil import * # Updated in V2.43 |
訓練參數與實際應用例子
關於函數參數的選擇應參考實際用途,涉及數學的參數應比對下邊document中定義之模型數學式比對計算。如L2-regularized LR在document中的數學定義為:

即:
應對比自己應用如:
計算C值作為參數傳入train函數中。
參考
- LIBLINEAR GitHub Repo
- LIBLINEAR Page
- https://blog.csdn.net/sinat_22548843/article/details/46931831