上章談到Node Embedding的overview,這次詳細談random walk這一embedding的方法之一。
如同字面上的意思,random walk就是從起始點隨機選一個鄰居節點作為下一個目的地(可以重複走同一edge),如此往復。

Random-Walk Embeddings
我們的目標是最大化
- Estimate probability of visiting node
on a random walk starting from node using some random walk strategy
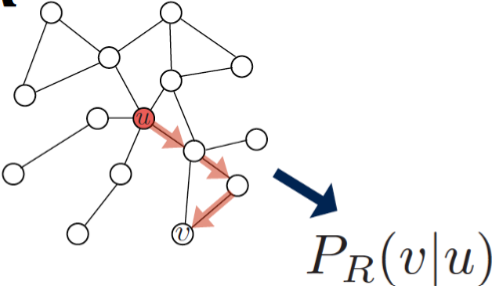
- Optimize embeddings to encode these random walk statistics:
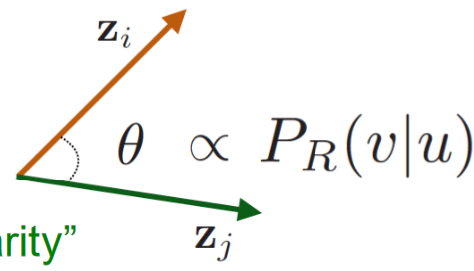
上圖中
Why Random Walks
- 易表達性:RW靈活多變的定義了node similarity,當從節點
走向節點 的概率較高時,我們認為 兩者的similarity較高 - 高效性:訓練時不用考慮所有的節點對,僅僅需要考慮出現在同一個RW中的節點對即可。
Feature Learning
接著我們用WR的概念來定義nearby nodes:
neighbourhood of obtained by some random walk strategy
在feature learning中我們的goal是獲得
這邊的
依以下步驟具體進行:
- Run short fixed-length random walks starting from each node
in the graph using some random walk strategy . - For each node
collect , the multiset(同一節點可能出現多次,因為可能被重複訪問) of nodes visited on random walks starting from . - Optimize embeddings according to: Given node
, predict its neighbors
而式一等價於式二:
接著為了讓節點
代入式二則得到式三:
最佳化RW embedding即找到使得
因為式三需要遍歷兩次整個graph,即複雜度為
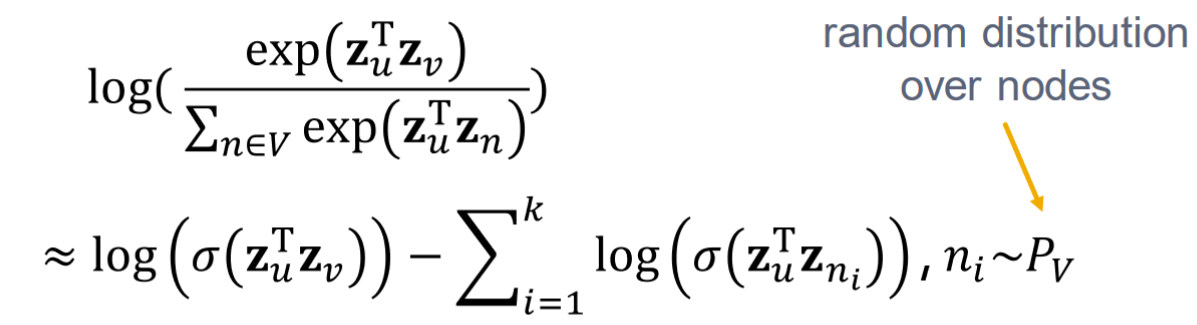
為什麼這樣的近似可以降低複雜度可參考: Negative Sampling
優化了複雜度後,我們回到主要的任務(即找到使得
Node2vec
上邊我們談到的是一種簡單的random walk策略(deep walk),即fixed-legth&unbiased。接下來提到的node2vec方法將更加豐富。
Key observation of Node2vec: Flexible notion of network neighborhood
of node leads to rich node embeddings. node2vec在如何選擇
這件事上更加靈活多遠,帶來更多的embedding可能性。
在如何選擇
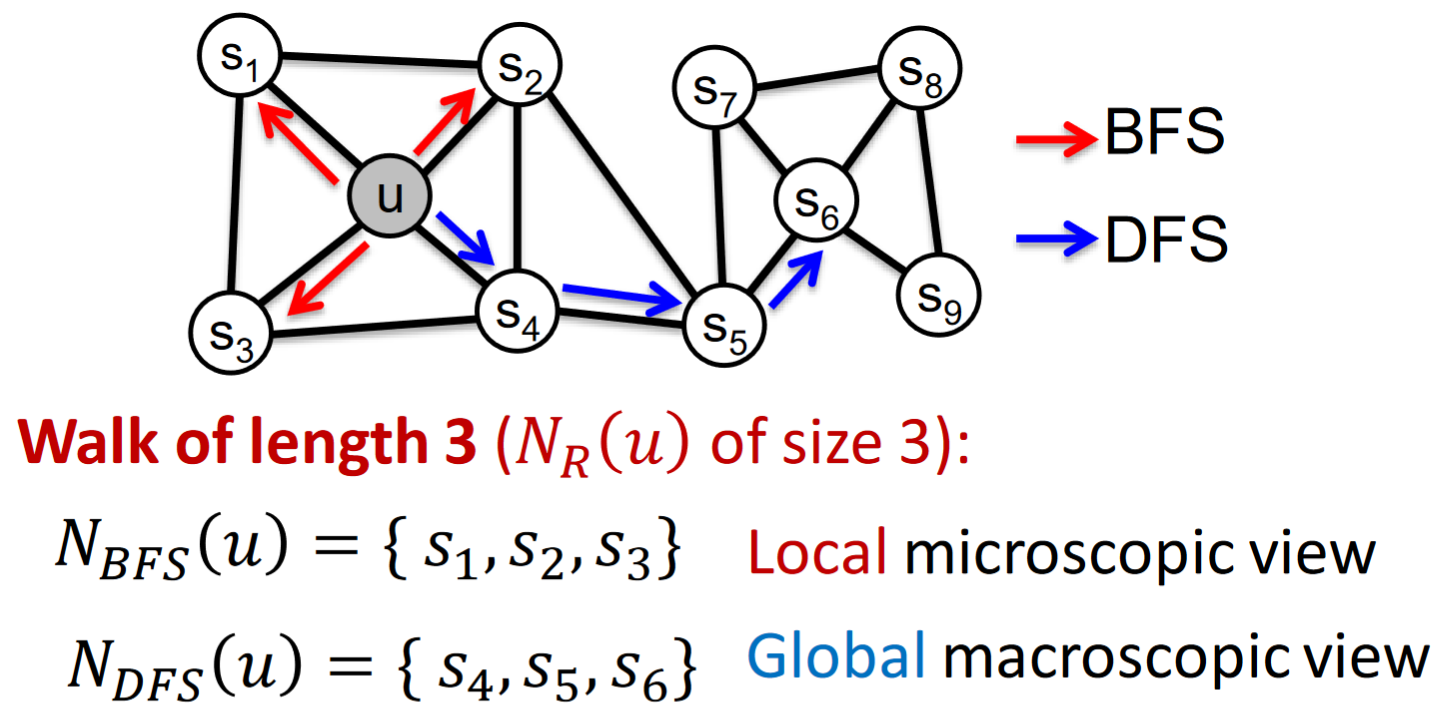
如何達到BFS和DFS兩種形式的遊走呢?考慮使用兩個參數來實現: *
這種形式叫做:Biased
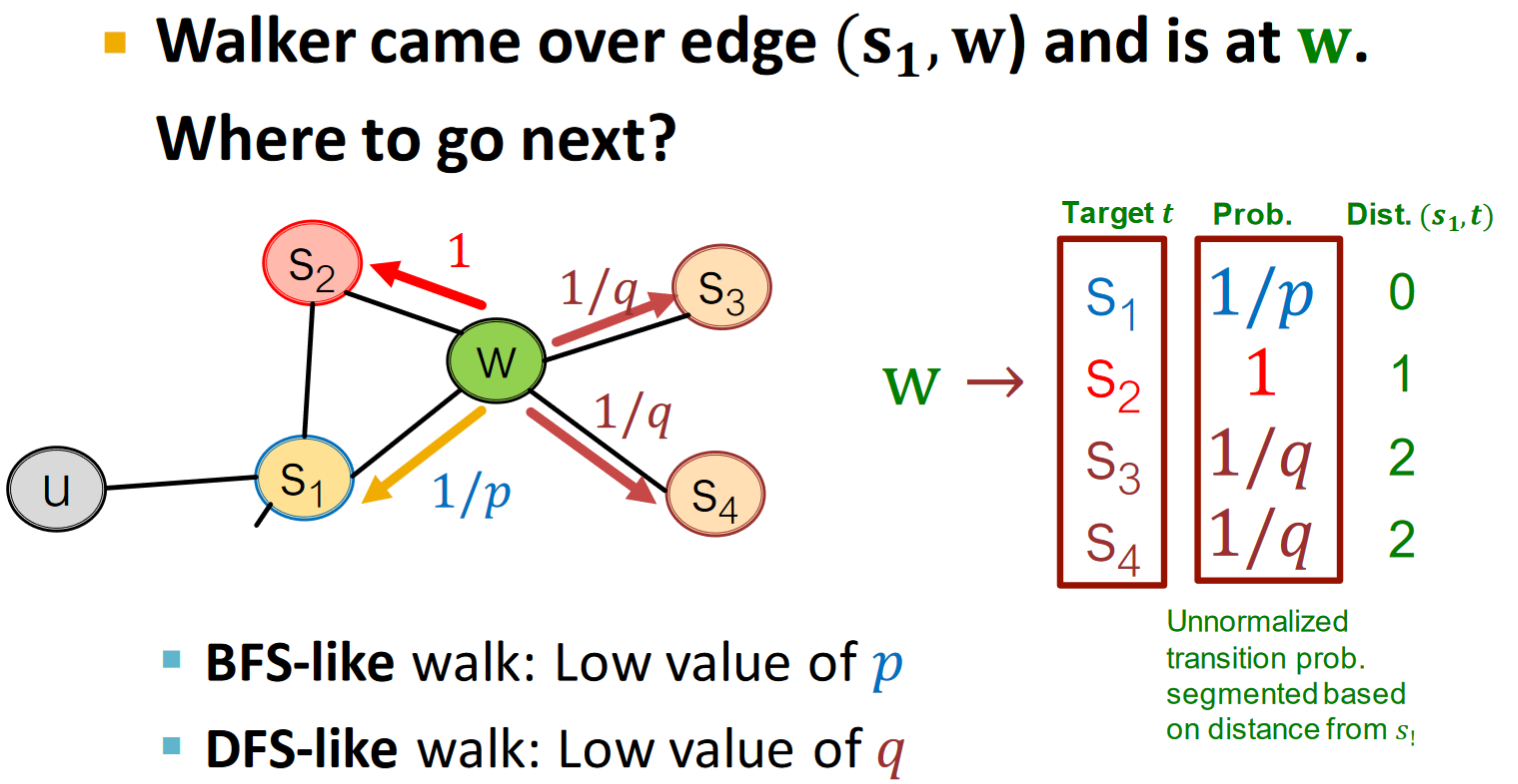
遊走從
Node2vec algorithm(三者可平行進行): 1. Compute random walk probabilities 2. Simulate
參考
- https://medium.com/@st3llasia/graph-embedding-techniques-7d5386c88c5
- http://web.stanford.edu/class/cs224w/