Traditional ML for Graphs
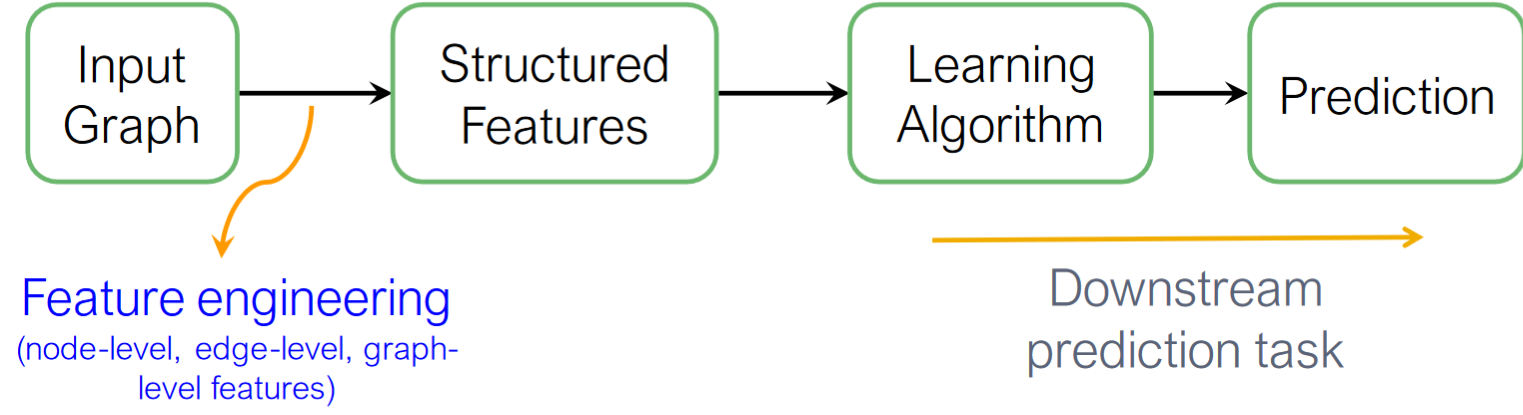
在傳統的Graph ML中我們通過Feature engineering 處理原始輸入的graph得到Structured Feature,再將這些結構化的特征輸入ML演算法中得到可供預測用的機器學習模型。
Graph Representation Learning
Graph Representation Learning alleviates the need to do feature engineering every single time.
i.e. Representation Learning: automatically learn the features. >
GRL目標在於由電腦自動的獲得feature,而不需要人工繁瑣的feature engineering.
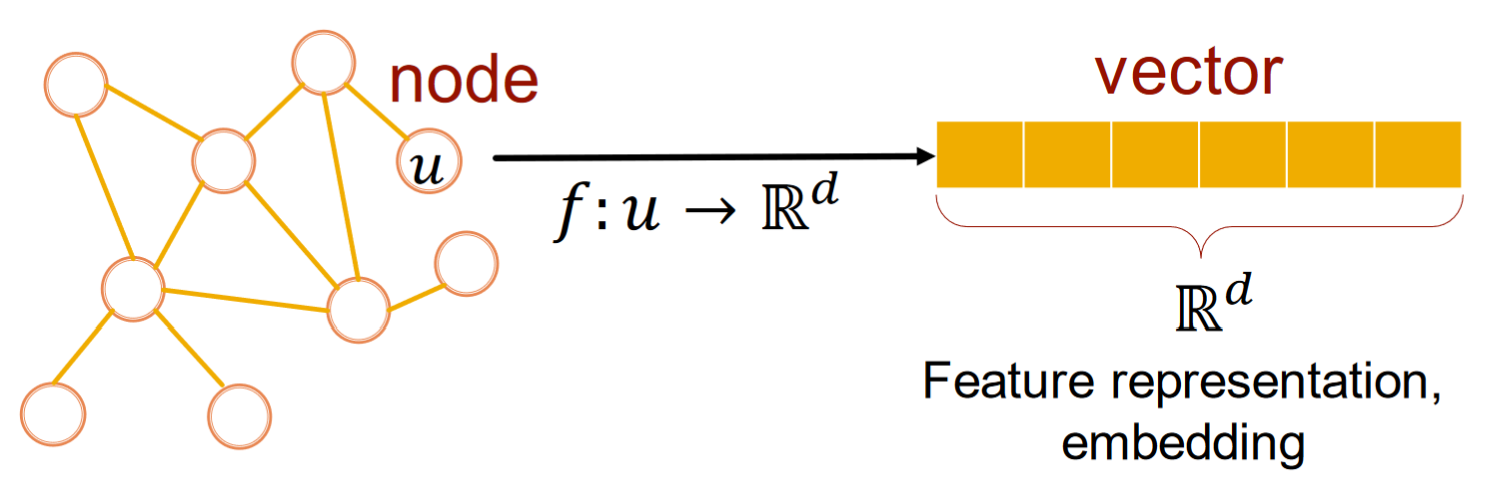
GRL如上圖,將node
Why Embedding
原先在graph相似度高的節點在經過embedding後也需要體現這種相似性。
Embedding這個過程可以看做Encode network information的過程。
Embedding的操作有利於下游做Node classification、link prediction等工作。
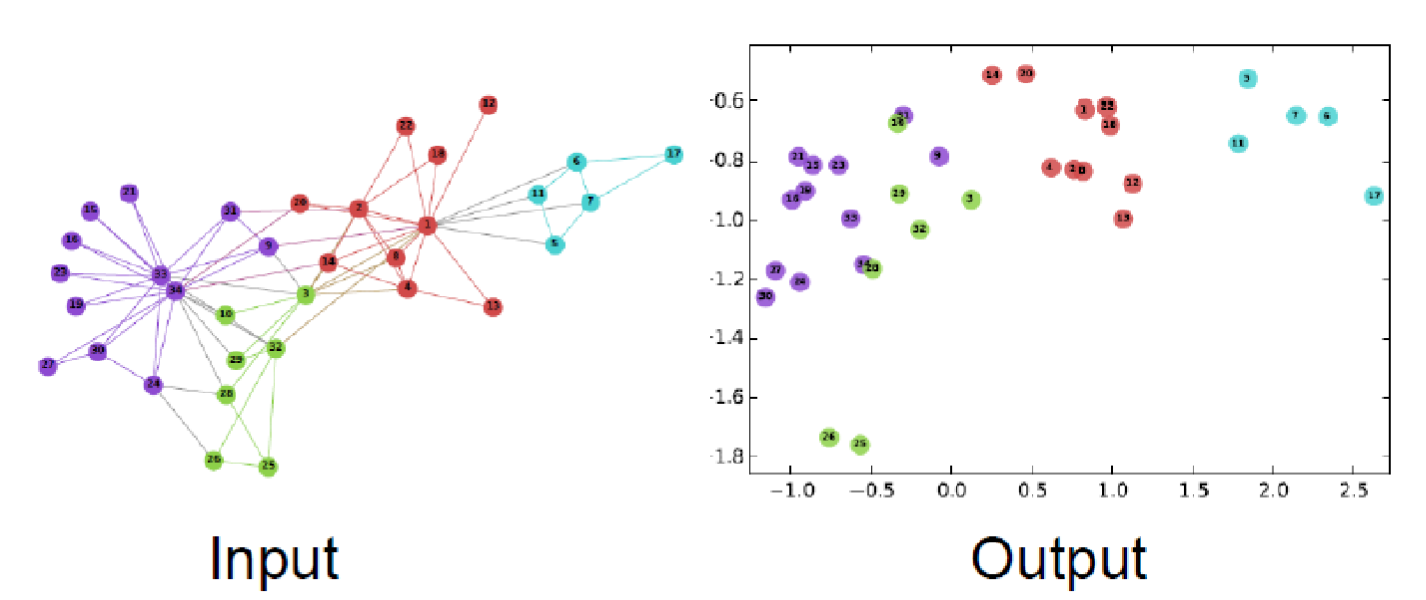
Example of node embedding:
A view of Node Embeddings: Encoder and Decoder
Goal: to encode nodes so that similarity in the embedding space(e.g. dot product) approximates similarity in the graph.
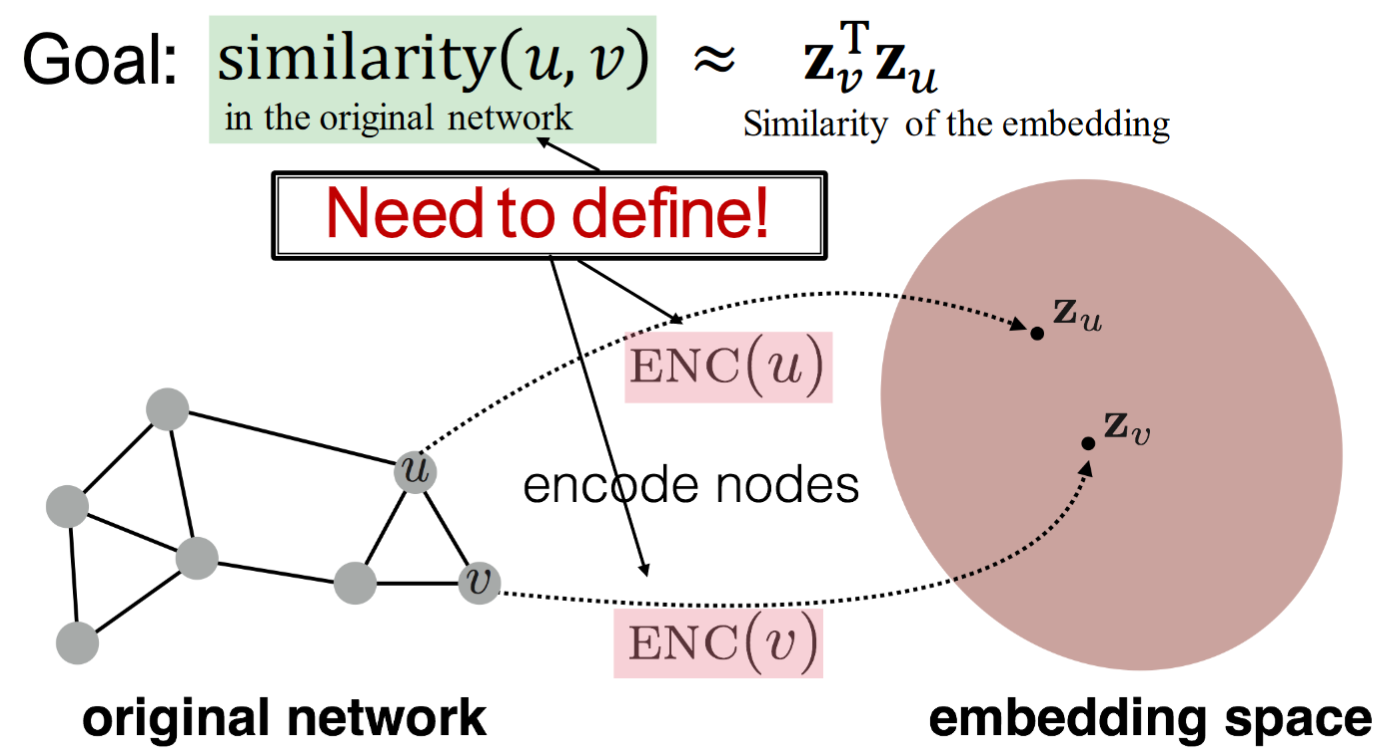
如上圖,將grpah中的節點通過ENC(encoder)對應到embedding space中(如圖中
流程:

Similarity function:
specifies how the relationships in vector space map to the relationship in the original network. i.e.
Shallow Encoding
一種簡單的encoding方式:
Z is the matrix which each column is a node embedding(what we learn/optimize)
v is the indicator vector, all zeros except a one in column indicating node
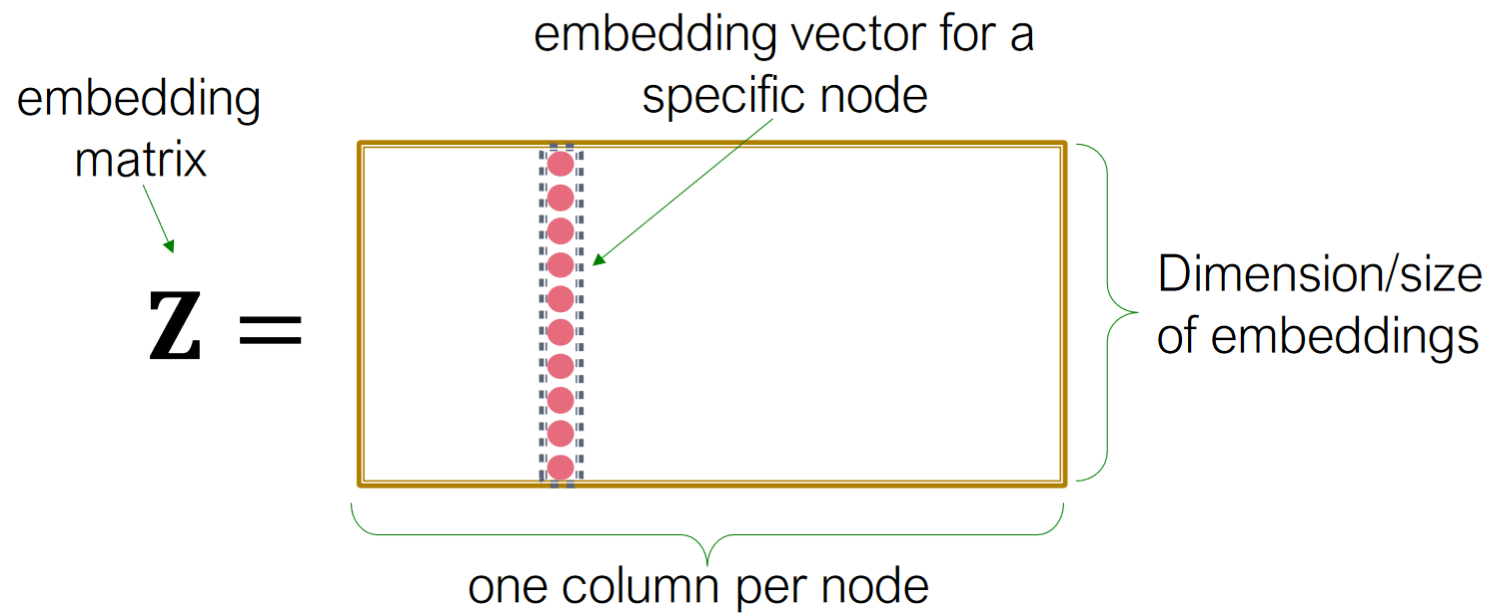
In this approach, each node is assigned a unique embedding vector. i.e. we directly optimize the embedding of each node.

參考
- http://web.stanford.edu/class/cs224w/